Da Sie sich mit SEO-Praktiken bestens auskennen, wissen Sie schon, was Duplicate Content ist, warum er schädlich für Ihr SEO sein könnte und wie Sie ihn erkennen und entfernen. Nein? Dann könnte dieser Ratgeber Ihnen ersparen, unnötige Einbußen in Ihrem SEO-Ranking hinnehmen zu müssen.
Was ist Duplicate Content überhaupt?
Wenn von Duplicate Content gesprochen wird, ist dabei von Inhalten die Rede, die nahezu identisch auf einer oder mehreren Domains zu finden sind. In der Regel handelt es sich bei diesen Inhalten um Texte und Textpassagen, allerdings oft auch um Inhaltsblöcke oder gar komplett kopierte Unterseiten. Kurzgesagt heißt dies, wenn derselbe Inhalt auf mehr als einer URL gefunden werden kann, handelt es sich dabei um Duplicate Content. Unterschieden wird hierbei zwischen internen und externen Duplikaten. Intern bedeutet, dass bestimmte Inhalte wiederholt unter der gleichen Domain auffindbar sind, z.B. auf einigen der Unterseiten. Extern wiederum sind Inhalte, wenn sie auf mehreren Domains zu finden sind.
Warum ist es ein Problem?
Für Google ist doppelter Inhalt bzw. wiederholt auftretender Inhalt durchaus problematisch. Googles Prioritäten sind u.a. für ein positives Suchergebnis seiner Nutzer garantieren zu können als auch seine eigenen Ressourcen nicht unnötig zu vergeuden. Duplicate Content ist diesen beiden Prioritäten sehr abträglich.
Suchergebnisse, die zum selben Inhalt führen, aber nicht dahingehend markiert sind, führen beim Nutzer nur für Verwirrung und für ein negatives Nutzererlebnis. Zudem ergibt sich auch eine andere Reihe an Problemen: Wenn mehrere Seiten, egal ob von derselben Domain – denselben Inhalt aufweisen, ist es für den Algorithmus von Google nicht ersichtlich, wie er die entsprechenden Webadressen hinsichtlich Trustfaktor, Relevanz und Link Authority einstufen soll. Die Folge kann sein, dass alle URLs mit diesem identischen Inhalt im Ranking herabgestuft werden. Es ist auch möglich, dass Google Duplicate Content als ein Täuschungsmanöver einstuft, was dazu führt, dass die entsprechende(n) Website(s) gänzlich aus den Suchergebnissen getilgt werden.
Daher ist es nur ratsam, Duplicate Content zu erkennen und zu entfernen bzw. diesen gar nicht erst zustande kommen zu lassen. Einige Grundlagen dazu gibt es von Google selbst.
Wie kommt es zustande?
Duplicate Content kann auf vielerlei Arten entstehen, viele davon unbeabsichtigt. Beispielsweise kann kann interne Duplikation alleine dadurch schon entstehen, dass eine Website sowohl über die URL ,,https://www.Website.de“ als auch ,,https://Website.de“ erreichbar ist. Selbiges Problem ergibt sich auch, wenn die Website eine an Mobilgeräte angepasste Website besitzt. Externe Duplikate können sowohl beabsichtigt oder auch unbeabsichtigt auftreten. Wenn andere Websites die eigenen Inhalte, sei es rechtmäßig durch Kooperationen oder unrechtmäßige Nutzung, so ist es eine – von der Haupt-website nicht herbeigeführte Duplikation. Wer allerdings beispielsweise für unterschiedliche Länderversionen seiner Website identische Inhalte verwendet, oder Artikel wie auch Pressemitteilungen von anderen Seiten identisch übernommen werden, handelt es sich um beabsichtigte Duplikate. Besonders diese werden von Google als Täuschungsmanöver interpretiert.
Wie erkenne ich Duplicate Content?

Um Duplicate Content zu erkennen, gibt es zahlreiche Optionen. Die einfachste und wahrlich offensichtlichste ist, wichtige Textabschnitte und Passagen über Google zu suchen. Die entsprechende Passage muss allerdings in Anführungszeichen gesetzt sein, damit es funktioniert. In vielen Fällen findet sich bei den Suchergebnissen ein Hinweis von Google, der mitteilt, dass einige Suchergebnisse aufgrund zu hoher Ähnlichkeit herausgefiltert wurden. Diese gilt es über den entsprechenden hervorgehobenen Link anzuzeigen und voila: Findet Google tatsächlich nennenswerte Ergebnisse, handelt es sich um Duplicate Content.
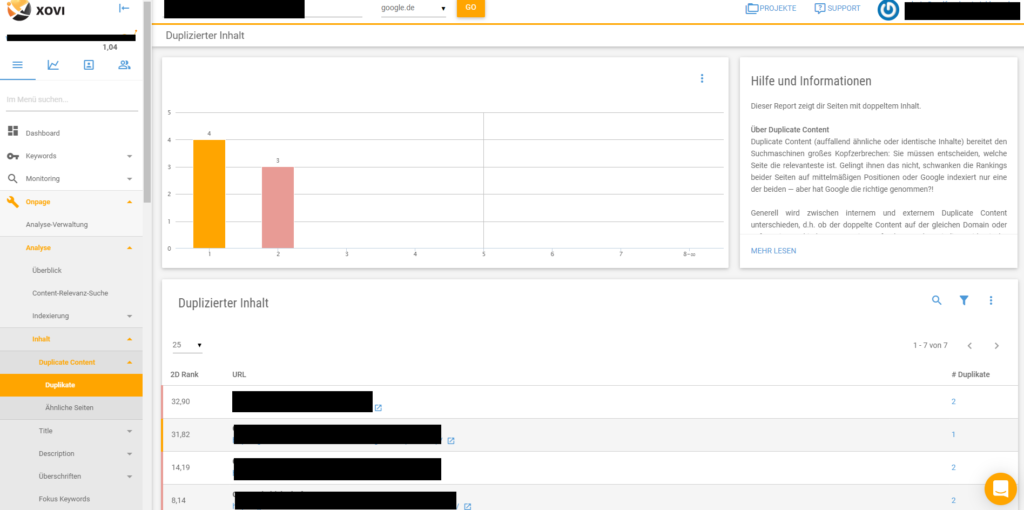
Alternativ gibt es auch eine Vielzahl an Tools, die nach Duplicate Content suchen. Xovi zum Beispiel ist eines davon. Über das Analyse-tool muss vorher ein Projekt mit entsprechender zu untersuchender Domain angelegt werden. Wenn man dann in der Kategorie ,,Onpage“ den Reiter ,,Analyse“ auswählt und von dort den Abschnitt ,,Inhalt“ anwählt, findet man dort die Option zur Untersuchung von Duplicate Content bei der im Projekt angegebenen Domain. Nach einigen Minuten Wartezeit bekommt man ein umfassendes Ergebnis, sowohl hinsichtlich identischer Duplikate als auch ähnlicher Seiten.
Neben Xovi gibt es aber auch einige kostenlose Tools. Diese dienen zwar auch der Duplicate-Content-Analyse, sind aber nicht immer so detailliert und aufschlussreich. Eines dieser kostenlosen Tools ist Siteliner.
Wie lässt sich Duplicate Content entfernen?
Viele Probleme hinsichtlich Duplicate Content, etwa die Erreichbarkeit der Seite über verschiedene URLs mit geringfügigen Unterschieden in der Domain, sind schnell behoben. Zum einen sollte man sich für eine der Schreibweisen der URL entscheiden und zusätzlich dazu eine 301 Weiterleitung in der htaccess-Datei anlegen. Das sähe dann in etwa so aus:
RewriteEngine on
RewriteCond %{HTTP_HOST} ^beispiel.de
RewriteRule ^(.*)$ https://beispiel.de$1 [R=301,L]oder
RewriteEngine on
RewriteCond %{HTTP_HOST} ^www.beispiel.de
RewriteRule ^(.*)$ http://beispiel.de$1 [R=301,L]Wenn eine Domain auf eine neue Seite umzieht, hilft auch in diesem Falle eine simple 301 Weiterleitung:
RedirectPermanent / https://domain-neu.deBei internen Duplikaten bieten Canonical Tags eine gute Lösung. Dadurch können Sie für Google die relevante URL kennzeichnen, um Missverständnissen vorzubeugen. Dazu schreibt Google: „ Kennzeichnen Sie die kanonische Seite und alle zugehörigen Varianten durch ein Linkelement rel=“canonical“. Fügen Sie ein-Element mit dem Attribut rel=“canonical“ zum Abschnitt
dieser Seiten hinzu:“. Wichtig ist hierbei, beim Linkelement rel=“canonical“ absolute statt relativer Pfade anzugeben. Anstatt dies manuell einzurichten, kann man dies auch einem SEO-Plugin überlassen. Die meisten WordPress-basierten Plugins (wie etwa Yoast oder SEORankMath) bieten die Option für Canonical Tags.Bei inhaltlichen Überschneidungen bieten sich eine ganze Reihe an Optionen an. Zum einen kann eine WDF*IDF-Analyse der Keywords (z.B. durch Xovi) eine Ausgangslage für die Überarbeitung der Keywords liefern. Außerdem bieten sich die Einbindung von Medien und anderen Einschüben in den Text sowie diverse SEO-Maßnahmen an (Überschriften, Titel und Meta-beschreibung anpassen).
Duplicate Content vermeiden
Vermeiden lässt sich die Doppelung von Inhalten, indem man die bereits genannten Maßnahmen sofort umsetzt. Darunter zählt die 301 Weiterleitung wie auch das Setzen von Canonical Tags. Beide dienen dem Zweck, auf die originale Seite des Inhalts zu verlinken. Dadurch bleibt Google und dem Nutzer gleichermaßen einiges an Verwirrung erspart. Alternativ lässt sich Duplicate Content vermeiden, indem man kürzere Passagen in seine Texte einbaut. So wird dem Text mehr Varianz und Individualität verliehen. Zudem ist es dadurch ,,unpraktischer“, längere Passagen zu kopieren.
Der wichtigste Tipp, um Duplicate Content zu erkennen, entfernen und zu vermeiden, ist aber folgender. Engagieren Sie uns! Dadurch bleibt Ihnen erspart, dass Duplicate Content entsteht oder Sie sich überhaupt damit befassen müssen!